



Familial Hypercholesterolemia via the LDLR Gene
Summary and Pricing 
Test Method
Exome Sequencing with CNV Detection| Test Code | Test Copy Genes | Test CPT Code | Gene CPT Codes Copy CPT Code | Base Price | |
|---|---|---|---|---|---|
| 12035 | LDLR | 81406 | 81406,81405 | $990 | Order Options and Pricing |
Pricing Comments
Our favored testing approach is exome based NextGen sequencing with CNV analysis. This will allow cost effective reflexing to PGxome or other exome based tests. However, if full gene Sanger sequencing is desired for STAT turnaround time, insurance, or other reasons, please see link below for Test Code, pricing, and turnaround time information. If the Sanger option is selected, CNV detection may be ordered through Test #600.
An additional 25% charge will be applied to STAT orders. STAT orders are prioritized throughout the testing process.
Click here for costs to reflex to whole PGxome (if original test is on PGxome Sequencing platform).
Click here for costs to reflex to whole PGnome (if original test is on PGnome Sequencing platform).
The Sanger Sequencing method for this test is NY State approved.
For Sanger Sequencing click here.Turnaround Time
3 weeks on average for standard orders or 2 weeks on average for STAT orders.
Please note: Once the testing process begins, an Estimated Report Date (ERD) range will be displayed in the portal. This is the most accurate prediction of when your report will be complete and may differ from the average TAT published on our website. About 85% of our tests will be reported within or before the ERD range. We will notify you of significant delays or holds which will impact the ERD. Learn more about turnaround times here.
Targeted Testing
For ordering sequencing of targeted known variants, go to our Targeted Variants page.
Clinical Features and Genetics
Clinical Features
Hypercholesterolemia is characterized by elevated serum levels of total cholesterol, in particular, elevated levels of low density lipoprotein (LDL) cholesterol (LDL-C) (>160 mg/dL in persons under 20 years of age, and >190 mg/dL in adults over 20 years of age (Hopkins et al. 2011. PubMed ID: 21600530). Accumulation of LDL-C can cause early onset atherosclerosis and Coronary Heart Disease (CHD). Familial hypercholesterolemia (FH) refers to high cholesterol that runs in a family. FH often leads to premature CHD and is one of the most common diseases of lipid metabolism. By age 50, approximately 45% of male and 20% of female FH patients suffer from coronary artery disease, a primary causative factor for CHD (Goldstein et al. 2001).
The prevalence of heterozygous FH (autosomal dominant FH) is between 1:300 and 1:500 in most countries and is much higher within certain populations, for example, 1:67 in Ashkenazi Jews (Goldstein et al. 1973. PubMed ID: 4718953; Vuorio et al. 1997. PubMed ID: 9409302; Slack 1979; Kalina et al. 2001. PubMed ID: 11137107; Austin et al. 2004. PubMed ID: 15321837). There are as many as 34 million people with FH worldwide, yet FH remains severely underdiagnosed with some studies suggesting <1% of possible FH patients have been identified in many countries (Sjouke et al. 2015. PubMed ID: 24585268; Nordestgaard et al., 2013. PubMed ID: 23956253).
Other symptoms of FH include fatty skin deposits called xanthomas, cholesterol deposits in the eyelids or in the peripheral corneal stroma (i.e. corneal arcus), and chest pains associated with coronary artery disease. FH is present from birth and confers a lifelong risk of atherosclerosis and CHD. Overall, patients with FH respond well to drug treatment making early, accurate diagnosis key factors for reducing risk of atherosclerosis and CHD.
Genetics
Several genes are reported to be associated with FH, however ~ 86% of FH patients are found to harbor pathogenic variants in either LDLR, APOB, PCSK9, which are associated with autosomal dominant FH, or in LDLRAP1 which is associated with autosomal recessive FH. Patients with biallelic variants in LDLR, APOB, or PCSK9, known as homozygous FH (HoFH), are rare and generally have a severe phenotype with a very high risk of early onset CHD. Pathogenic variants in the LDLR gene are the most frequent cause of FH and account for ~ 79% of cases, though reported percentages of LDLR-related FH range from 37% to 97% depending upon the particular study (Varret et al. 2008. PubMed ID: 18028451; Tosi et al. 2007. PubMed ID: 17094996; Bertolini et al. 2013. PubMed ID: 23375686).
LDLR encodes the LDL receptor that binds LDL-C at the surface of hepatocytes. Loss of function variants in LDLR impede LDL-C binding and endocytosis that results in high levels of cholesterol in blood and arteries and formation of xanthomas and atherosclerotic plaques (Hobbs et al. 1990. PubMed ID: 2088165; Varret et al. 2008. PubMed ID: 18028451). Over 2,000 probable pathogenic variants have been reported in the LDLR gene. Variants are located throughout LDLR and comprised primarily of missense/nonsense variants. Splice site variants and deletions and insertions are also fairly common with over 10% of reported variants being large deletions or insertions (Human Gene Mutation Database). There is also some evidence to suggest that patients who harbor pathogenic variants in two FH genes, e.g. the LDLR and LDLRAP1 genes, may have a more severe form of FH or additional clinical characteristics that may not be present in patients that harbor a causative variant in only one FH gene (Tada et al. 2011. PubMed ID: 21872251; Alnouri et al. 2018. PubMed ID: 30270081).
Clinical Sensitivity - Sequencing with CNV PGxome
Pathogenic variants in LDLR are the most frequent cause of heterozygous Familial Hypercholesterolemia (FH) followed by variants in APOB, PCSK9, and LDLRAP1. The exact proportion of pathogenic variants within these genes varies among populations, but data from several studies indicate the contribution of LDLR, APOB, and PCSK9 pathogenic variants to FH cases ranges from 37-97%, 0-7%, and 0-3%, respectively (Varret et al. 2008. PubMed ID: 18028451; Tosi et al. 2007. PubMed ID: 17094996; Bertolini et al. 2013. PubMed ID: 23375686). The frequency of LDLRAP1/ARH variants in recessive FH is unclear, but the carrier frequency has been reported to be as high as 1:143 in the Sardinian population (Filigheddu et al. 2009. PubMed ID: 19477448).
Over 15% of pathogenic variants reported for the LDLR and LDLRAP1 genes are either large deletions or insertions (Human Gene Mutation Database). Few large deletions or insertions in the APOB and PCSK9 genes have been reported.
Testing Strategy
This test provides full coverage of all coding exons of the LDLR gene plus 10 bases of flanking noncoding DNA in all available transcripts along with other non-coding regions in which pathogenic variants have been identified at PreventionGenetics or reported elsewhere. We define full coverage as >20X NGS reads or Sanger sequencing. PGnome panels typically provide slightly increased coverage over the PGxome equivalent. PGnome sequencing panels have the added benefit of additional analysis and reporting of deep intronic regions (where applicable).
Dependent on the sequencing backbone selected for this testing, discounted reflex testing to any other similar backbone-based test is available (i.e., PGxome panel to whole PGxome; PGnome panel to whole PGnome).
Indications for Test
Patients with high levels of LDL, and/or a strong family history of hypercholesterolemia or coronary heart disease. Patients with xanthomas, corneal arcus, or angina.
Patients with high levels of LDL, and/or a strong family history of hypercholesterolemia or coronary heart disease. Patients with xanthomas, corneal arcus, or angina.
Gene
| Official Gene Symbol | OMIM ID |
|---|---|
| LDLR | 606945 |
| Inheritance | Abbreviation |
|---|---|
| Autosomal Dominant | AD |
| Autosomal Recessive | AR |
| X-Linked | XL |
| Mitochondrial | MT |
Disease
| Name | Inheritance | OMIM ID |
|---|---|---|
| Familial Hypercholesterolemia | AD | 143890 |
Citations
- Alnouri et al. 2018. PubMed ID: 30270081
- Austin et al. 2004. PubMed ID: 15321837
- Bertolini et al. 2013. PubMed ID: 23375686
- Filigheddu et al. 2009. PubMed ID: 19477448
- Goldstein et al. 1973. PubMed ID: 4718953
- Goldstein et al. 2001. In: The Metabolic and Molecular Basis of Inherited Disease - 8th edition (edited by C.R. Scriver et al.) New York: McGraw-Hill.
- Hobbs et al. 1990. PubMed ID: 2088165
- Hopkins et al. 2011. PubMed ID: 21600530
- Human Gene Mutation Database (Bio-base).
- Kalina et al. 2001. PubMed ID: 11137107
- Nordestgaard et al. 2013. PubMed ID: 23956253
- Sjouke et al. 2015. PubMed ID: 24585268
- Slack. 1979. Atherosclerosis Reviews. 5: 35-66.
- Tada et al. 2011. PubMed ID: 21872251
- Tosi et al. 2007. PubMed ID: 17094996
- Varret et al. 2008. PubMed ID: 18028451
- Vuorio et al. 1997. PubMed ID: 9409302
Ordering/Specimens
Ordering Options
We offer several options when ordering sequencing tests. For more information on these options, see our Ordering Instructions page. To view available options, click on the Order Options button within the test description.
myPrevent - Online Ordering
- The test can be added to your online orders in the Summary and Pricing section.
- Once the test has been added log in to myPrevent to fill out an online requisition form.
- PGnome sequencing panels can be ordered via the myPrevent portal only at this time.
Requisition Form
- A completed requisition form must accompany all specimens.
- Billing information along with specimen and shipping instructions are within the requisition form.
- All testing must be ordered by a qualified healthcare provider.
For Requisition Forms, visit our Forms page
If ordering a Duo or Trio test, the proband and all comparator samples are required to initiate testing. If we do not receive all required samples for the test ordered within 21 days, we will convert the order to the most effective testing strategy with the samples available. Prior authorization and/or billing in place may be impacted by a change in test code.
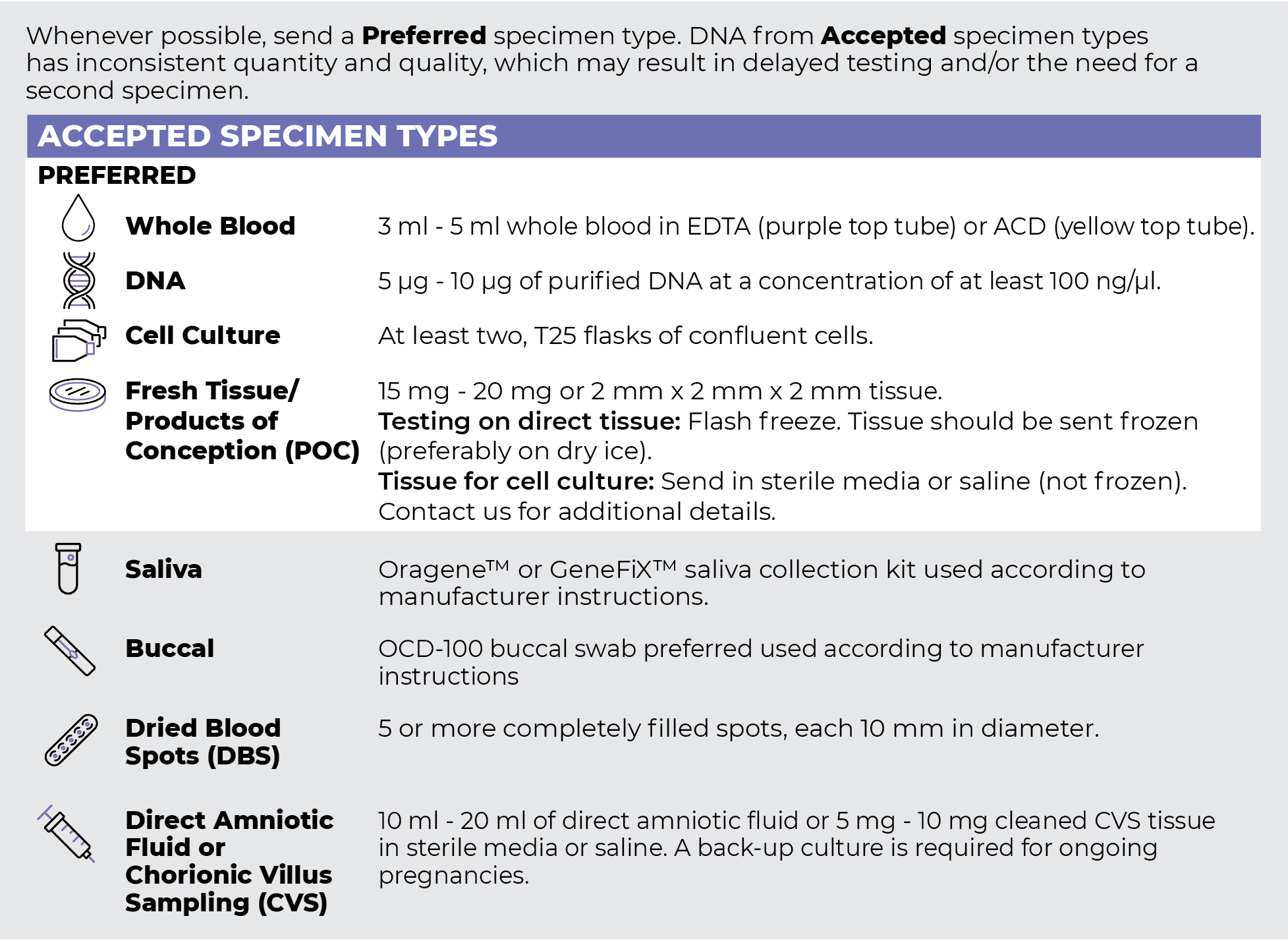
Specimen Types
Specimen Requirements and Shipping Details
PGxome (Exome) Sequencing Panel
PGnome (Genome) Sequencing Panel

ORDER OPTIONS
View Ordering Instructions1) Select Test Type
2) Select Additional Test Options
No Additional Test Options are available for this test.