



Congenital Hyperinsulinism Panel
Summary and Pricing 
Test Method
Exome Sequencing with CNV Detection| Test Code | Test Copy Genes | Panel CPT Code | Gene CPT Codes Copy CPT Code | Base Price | |
|---|---|---|---|---|---|
| 10265 | Genes x (9) | 81479 | 81403(x1), 81405(x1), 81406(x3), 81407(x1), 81479(x12) | $990 | Order Options and Pricing |
Pricing Comments
We are happy to accommodate requests for testing single genes in this panel or a subset of these genes. The price will remain the list price. If desired, free reflex testing to remaining genes on panel is available. Alternatively, a single gene or subset of genes can also be ordered via our Custom Panel tool.
An additional 25% charge will be applied to STAT orders. STAT orders are prioritized throughout the testing process.
Click here for costs to reflex to whole PGxome (if original test is on PGxome Sequencing platform).
Click here for costs to reflex to whole PGnome (if original test is on PGnome Sequencing platform).
Turnaround Time
3 weeks on average for standard orders or 2 weeks on average for STAT orders.
Please note: Once the testing process begins, an Estimated Report Date (ERD) range will be displayed in the portal. This is the most accurate prediction of when your report will be complete and may differ from the average TAT published on our website. About 85% of our tests will be reported within or before the ERD range. We will notify you of significant delays or holds which will impact the ERD. Learn more about turnaround times here.
Targeted Testing
For ordering sequencing of targeted known variants, go to our Targeted Variants page.
Clinical Features and Genetics
Clinical Features
Congenital hyperinsulinism (CHI) is a clinically and genetically heterogeneous condition characterized by hypoglycemia (Glaser et al. 2003; Arnoux et al. 2010). The age of disease onset ranges from the neonatal period with severe forms to infancy or childhood with milder forms. Severe patients typically have extremely low serum glucose while milder cases present with variable hypoglycemia. Affected newborns also develop nonspecific symptoms including seizures, apnea, hypotonia, and poor feeding. Severity of disease manifestations can vary within the same family.
Genetics
CHI is genetically caused by defects in genes involved in regulation of insulin secretion from pancreatic beta-cells (Kapoor et al. 2013; Snider et al. 2013). CHI can be inherited in an autosomal dominant or recessive manner. Proteins encoded by CHI-associated genes include the ATP-sensitive potassium (KATP) channels (ABCC8 and KCNJ11), the glutamate dehydrogenase (GLUD1), nuclear transcription factors controlling pancreatic development (HNF1A and HNF4A), the glucokinase (a glucose sensor in pancreatic beta-cells) (GCK), a member of the 3-hydroxyacyl-CoA dehydrogenase family (HADH), a mitochondrial anion carrier protein (UCP2) and a plasma membrane pyruvate transporter (SLC16A1) (Glaser et al. 2003; Kapoor et al. 2013; Snider et al. 2013). Our current CHI NGS panel covers all 9 genes.
Defects in KATP channels (ABCC8 and KCNJ11) are the most common cause of CHI. KATP-associated CHI can be inherited in an autosomal recessive or dominant manner. ABCC8 has 39 coding exons that encode the sulfonylurea receptor 1 (SUR1) subunit of the ATP-sensitive potassium (KATP) channels in beta-cells. Genetic defects located throughout the ABCC8 gene have a wide mutation spectrum including missense, nonsense, regulatory, splicing site mutations, small deletion/insertions, large deletions/duplications, and complex rearrangements (Human Gene Mutation Database).
KCNJ11 is a single exon gene that encodes the Kir6.2 subunit of the ATP-sensitive potassium (KATP) channels in beta-cells. Genetic defects located throughout the KCNJ11 gene include missense, nonsense, regulatory, and small deletion/insertions (Human Gene Mutation Database).
GLUD1-caused congenital hyperinsulinism (hyperinsulinism-hyperammonemia syndrome) is the second most common type of CHI caused by dominant activating mutations in the GLUD1 gene (13 coding exons), which encodes glutamate dehydrogenase (GDH). This enzyme is a potential regulator of insulin secretion in pancreatic beta cells and of ureagenesis in the liver.
The third most common causes of CHI are dominant activating mutations in the GCK gene (10 coding exons), which encodes glucokinase. Dominant inactivating GCK mutations cause MODY type 2 (MODY2) (McDonald et al. 2013). More information about GCK can be found in the Test #1220 Description (Sanger sequencing).
The HADH gene (9 coding exons) encodes short-chain L-3-hydroxyacyl-CoA dehydrogenase, a fatty acid oxidation enzyme in the mitochondrial matrix. Recessive inactivating HADH mutations can cause CHI (Clayton et al. 2001).
The UCP2 gene (6 coding exons) encodes a mitochondrial uncoupling protein involved in nonshivering thermogenesis, obesity and diabetes. Dominant inactivating UCP2 mutations can cause CHI (Gonzalez-Barroso et al. 2008).
The genes HNF1A (also known as TCF1; 10 coding exons) and HNF4A (10 coding exons) encode hepatocyte nuclear factor 1-alpha and 4-alpha, respectively. These hepatic nuclear factor transcription factors regulate the expression of insulin as well as alter beta-cell development, proliferation and cell death in the mature beta-cells. Defects in HNF1A and HNF4A are the major cause of maturity onset diabetes of the young (MODY) (McDonald et al. 2013). In addition, dominant mutations in both HNF1A and HNF4A can cause CHI early in life and diabetes later (Stanescu et al. 2012).
The SLC16A1 gene (4 coding exons) encodes a plasma membrane monocarboxylate transporter 1 (MCT1). Dominant activating SLC16A1 mutations cause exercise-induced CHI secondary to failed silencing of monocarboxylate transporter 1 in pancreatic beta cells (Otonkoski et al. 2007).
Clinical Sensitivity - Sequencing with CNV PGxome
In a cohort of 417 CHI patients studied at the Hyperinsulinism Center in The Children’s Hospital of Philadelphia (CHOP) (Snider et al. 2013), all nine genes were tested. Mutations were identified in 91% (272 of 298) of diazoxide-unresponsive probands (ABCC8, KCNJ11, and GCK), and in 47% (56 of 118) of diazoxide-responsive probands (ABCC8, KCNJ11, GLUD1, HADH, UCP2, HNF4A, and HNF1A). In another cohort of 300 CHI patients studied in United Kingdom (Kapoor et al. 2013), mutations were identified in 45.3% of patients (136/300) in eight tested genes (ABCC8, KCNJ11, GLUD1, GCK, HADH, SLC16A1, HNF4A and HNF1A). KATP (ABCC8 and KCNJ11) mutations were the most common genetic cause identified (109/300, 36.3%). Mutations in ABCC8/KCNJ11 were identified in 92 (87.6%) diazoxide-unresponsive patients (n=105). Among the diazoxide-responsive patients (n=183), mutations were identified in 41 patients (22.4%), including mutations in ABCC8/KCNJ11 (15), HNF4A (7), GLUD1 (16) and HADH (3).
Clinical sensitivity for gross deletions and duplications in the HADH gene cannot be predicted as few patients have been reported. One gross deletion has been reported (Human Gene Mutation Database).
Testing Strategy
This test is performed using Next-Gen sequencing with additional Sanger sequencing as necessary.
This panel provides 100% coverage of all coding exons of the genes plus 10 bases of flanking noncoding DNA in all available transcripts along with other non-coding regions in which pathogenic variants have been identified at PreventionGenetics or reported elsewhere. We define coverage as ≥20X NGS reads or Sanger sequencing. PGnome panels typically provide slightly increased coverage over the PGxome equivalent. PGnome sequencing panels have the added benefit of additional analysis and reporting of deep intronic regions (where applicable).
Dependent on the sequencing backbone selected for this testing, discounted reflex testing to any other similar backbone-based test is available (i.e., PGxome panel to whole PGxome; PGnome panel to whole PGnome).
Indications for Test
Candidates for this test are patients with CHI. This test especially aids in a differential diagnosis of similar phenotypes by analyzing multiple genes simultaneously.
Candidates for this test are patients with CHI. This test especially aids in a differential diagnosis of similar phenotypes by analyzing multiple genes simultaneously.
Genes
| Official Gene Symbol | OMIM ID |
|---|---|
| ABCC8 | 600509 |
| GCK | 138079 |
| GLUD1 | 138130 |
| HADH | 601609 |
| HNF1A | 142410 |
| HNF4A | 600281 |
| KCNJ11 | 600937 |
| SLC16A1 | 600682 |
| UCP2 | 601693 |
| Inheritance | Abbreviation |
|---|---|
| Autosomal Dominant | AD |
| Autosomal Recessive | AR |
| X-Linked | XL |
| Mitochondrial | MT |
Diseases
Related Test
| Name |
|---|
| PGxome® |
Citations
- Arnoux J.B. et al. 2010. Early Human Development. 86: 287-94. PubMed ID: 20550977
- Clayton PT, Eaton S, Aynsley-Green A, Edginton M, Hussain K, Krywawych S, Datta V, Malingre HE, Berger R, Berg IE van den. 2001. Hyperinsulinism in short-chain L-3-hydroxyacyl-CoA dehydrogenase deficiency reveals the importance of beta-oxidation in insulin secretion. J. Clin. Invest. 108: 457–465. PubMed ID: 11489939
- Glaser B. 2003. Familial Hyperinsulinism. In: Pagon RA, Adam MP, Ardinger HH, Bird TD, Dolan CR, Fong C-T, Smith RJ, and Stephens K, editors. GeneReviews(®), Seattle (WA): University of Washington, Seattle. PubMed ID: 20301549
- González-Barroso M.M. et al. 2008. Plos One. 3: e3850. PubMed ID: 19065272
- Human Gene Mutation Database (Bio-base).
- Kapoor R.R. et al. 2013. European Journal of Endocrinology / European Federation of Endocrine Societies. 168: 557-64. PubMed ID: 23345197
- McDonald T.J., Ellard S. 2013. Annals of Clinical Biochemistry. 50: 403-15. PubMed ID: 23878349
- Otonkoski T, Jiao H, Kaminen-Ahola N, Tapia-Paez I, Ullah MS, Parton LE, Schuit F, Quintens R, Sipilä I, Mayatepek E, Meissner T, Halestrap AP, et al. 2007. Physical exercise-induced hypoglycemia caused by failed silencing of monocarboxylate transporter 1 in pancreatic beta cells. Am. J. Hum. Genet. 81: 467–474. PubMed ID: 17701893
- Snider K.E. et al. 2013. The Journal of Clinical Endocrinology and Metabolism. 98: E355-63. PubMed ID: 23275527
- Stanescu DE, Hughes N, Kaplan B, Stanley CA, León DD De. 2012. Novel presentations of congenital hyperinsulinism due to mutations in the MODY genes: HNF1A and HNF4A. J. Clin. Endocrinol. Metab. 97: E2026–2030. PubMed ID: 22802087
Ordering/Specimens
Ordering Options
We offer several options when ordering sequencing tests. For more information on these options, see our Ordering Instructions page. To view available options, click on the Order Options button within the test description.
myPrevent - Online Ordering
- The test can be added to your online orders in the Summary and Pricing section.
- Once the test has been added log in to myPrevent to fill out an online requisition form.
- PGnome sequencing panels can be ordered via the myPrevent portal only at this time.
Requisition Form
- A completed requisition form must accompany all specimens.
- Billing information along with specimen and shipping instructions are within the requisition form.
- All testing must be ordered by a qualified healthcare provider.
For Requisition Forms, visit our Forms page
If ordering a Duo or Trio test, the proband and all comparator samples are required to initiate testing. If we do not receive all required samples for the test ordered within 21 days, we will convert the order to the most effective testing strategy with the samples available. Prior authorization and/or billing in place may be impacted by a change in test code.
Specimen Types
Specimen Requirements and Shipping Details
PGxome (Exome) Sequencing Panel
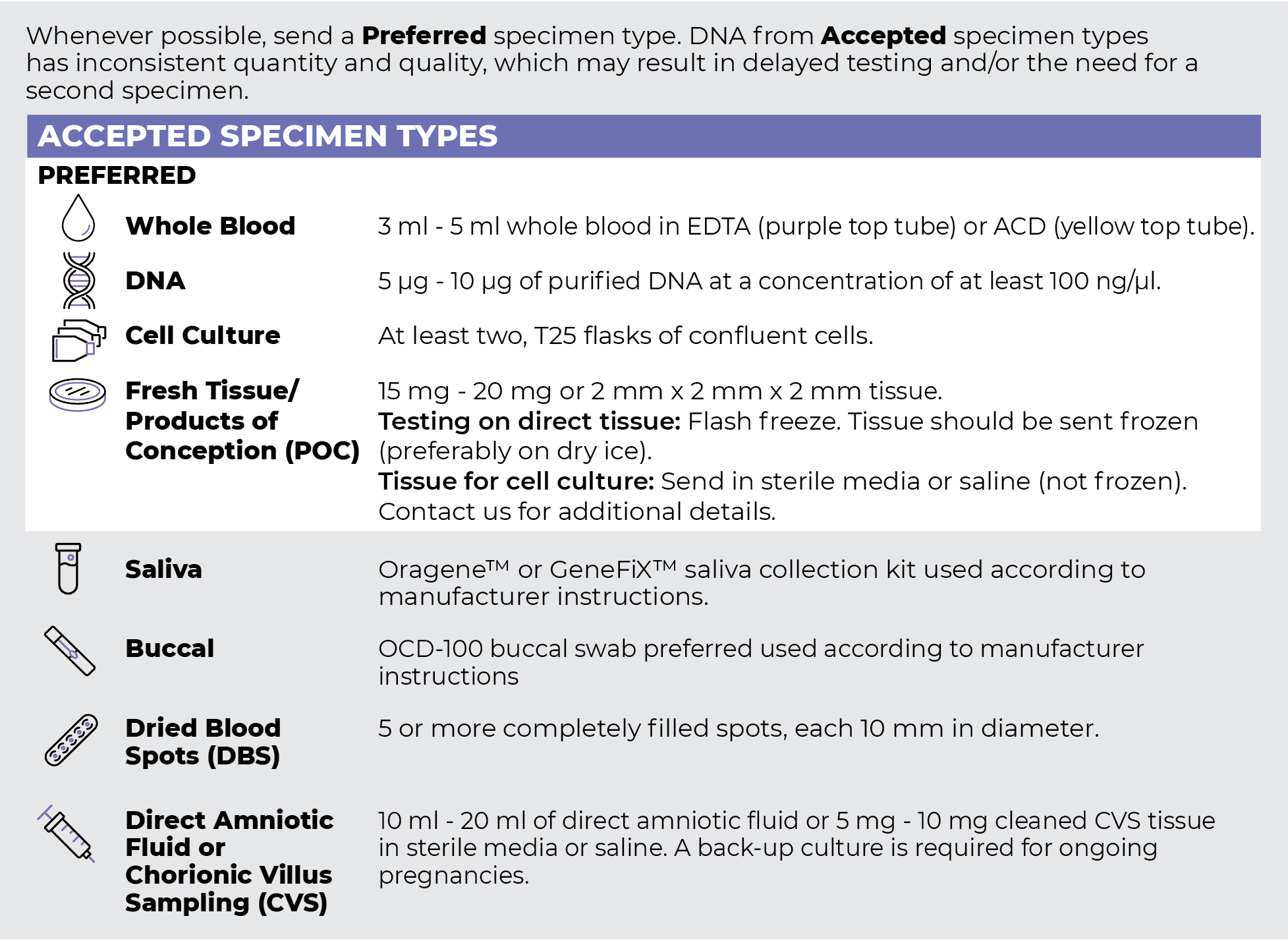
PGnome (Genome) Sequencing Panel

ORDER OPTIONS
View Ordering Instructions1) Select Test Type
2) Select Additional Test Options
No Additional Test Options are available for this test.