



Autosomal Dominant and Recessive Polycystic Kidney Disease (ADPKD and ARPKD) Panel
Summary and Pricing 
Test Method
Exome Sequencing with CNV Detection| Test Code | Test Copy Genes | Panel CPT Code | Gene CPT Codes Copy CPT Code | Base Price | |
|---|---|---|---|---|---|
| 10189 | Genes x (13) | 81479 | 81404(x1), 81405(x1), 81406(x1), 81407(x1), 81408(x1), 81479(x21) | $990 | Order Options and Pricing |
Pricing Comments
We are happy to accommodate requests for testing single genes in this panel or a subset of these genes. The price will remain the list price. If desired, free reflex testing to remaining genes on panel is available. Alternatively, a single gene or subset of genes can also be ordered via our Custom Panel tool.
An additional 25% charge will be applied to STAT orders. STAT orders are prioritized throughout the testing process.
Click here for costs to reflex to whole PGxome (if original test is on PGxome Sequencing platform).
Click here for costs to reflex to whole PGnome (if original test is on PGnome Sequencing platform).
Turnaround Time
3 weeks on average for standard orders or 2 weeks on average for STAT orders.
Please note: Once the testing process begins, an Estimated Report Date (ERD) range will be displayed in the portal. This is the most accurate prediction of when your report will be complete and may differ from the average TAT published on our website. About 85% of our tests will be reported within or before the ERD range. We will notify you of significant delays or holds which will impact the ERD. Learn more about turnaround times here.
Targeted Testing
For ordering sequencing of targeted known variants, go to our Targeted Variants page.
Clinical Features and Genetics
Clinical Features
Autosomal dominant polycystic kidney disease (ADPKD) is a common inherited kidney disease with multisystem involvement. ADPKD is characterized by bilateral renal cysts accompanied by cysts in other organs including the liver, seminal vesicles, pancreas, and arachnoid membrane (Harris et al. 2011. PubMed ID: 20301424). Renal symptoms include hypertension, renal pain, and renal insufficiency. Nearly half of ADPKD patients have end-stage renal disease (ESRD) by age 60 years. The progressive growth of liver cysts is the most common extrarenal manifestation of ADPKD. The most important non-cystic manifestations of ADPKD are vascular and cardiac abnormalities including intracranial aneurysms, mitral valve prolapse, dilatation of the aortic root, dissection of the thoracic aorta, and abdominal wall hernias. The clinical spectrum of ADPKD is wide and substantial variability of disease severity can occur even within the same family.
Patients with ADPKD typically have onset of symptoms in adulthood. In some rare cases, however, patients with bi-allelic PKD1 variants may have clinical features similar to those of patients with autosomal recessive polycystic kidney disease (ARPKD) (Rossetti et al. 2009. PubMed ID: 19165178; Vujic et al. 2010. PubMed ID: 20558538; Audrézet et al. 2016. PubMed ID: 26139440). In these rare cases, symptoms may appear in early childhood or even in utero.
Autosomal recessive polycystic kidney disease (ARPKD) is a hepatorenal fibrocystic disorder characterized by enlarged kidneys with collecting duct cysts and congenital hepatic fibrosis due to ductal plate malformation (DPM) during development (Bergmann. 2017. PubMed ID: 29479522; Sweeney et al. 1993. PubMed ID: 20301501). Arterial hypertension often develops during the first months of life and affects up to 80% of children with ARPKD. Severity varies widely and the most severe cases are often neonatal lethal (approximately 30% of ARPKD patients with pathogenic variants in PKHD1). Diagnosis is often made pre- or neonatally although some cases are diagnosed in childhood or adult life. Many who survive the newborn period progress to end stage renal disease (ESRD).
HNF1B defects alone cause renal cysts and diabetes syndrome (RCAD), also referred to as maturity-onset diabetes of the young type 5 (MODY5) (Horikawa et al. 1997. PubMed ID: 9398836; McDonald and Ellard. 2013. PubMed ID: 23878349). In addition, HNF1B is considered a causative gene for the spectrum of congenital anomalies of the kidney and urinary tract (CAKUT) (Vivante et al. 2014. PubMed ID: 24398540). Concurrent HNF1B and PKD1 pathogenic variants have been reported to have an aggravating effect on a patient's phenotypes and help to explain phenotypic variabilities within PKD-affected family members (Bergmann et al. 2011. PubMed ID: 22034641).
Genetics
PKD1 and PKD2 are the two major causative genes for ADPKD (Rossetti et al. 2007. PubMed ID: 17582161; Audrézet et al. 2012. PubMed ID: 22508176). Accounting for a small fraction of ADPKD cases, GANAB and DNAJB11 were newly implicated in ADPKD (Porath et al. 2016. PubMed ID: 27259053; Cornec-Le Gall et al. 2018. PubMed ID: 29706351).
Genetic defects in PKD1 and PKD2 explain approximately 85% and 15% of genetically positive ADPKD cases, respectively (Rossetti et al. 2007. PubMed ID: 17582161; Audrézet et al. 2012. PubMed ID: 22508176). Both genes encode members of the polycystin protein family, which together play an important role in renal tubular development. These pathogenic variants have been found across the whole coding region of both genes. Truncated variants (nonsense, canonical splicing variants and frame-shifting small deletion/insertions) are the majority of PKD1 and PKD2 defects while missense variants and small in-frame changes are also commonly found. Large deletions and duplications have been reported, but are relatively uncommon (<4% of pathogenic variants) (Ariyurek et al. 2004. PubMed ID: 14695542; Rossetti et al. 2007. PubMed ID: 17582161; Audrézet et al. 2012. PubMed ID: 22508176). Our internal data suggested gene conversions are rare (<0.5%) in PKD1. The majority of PKD1 and PKD2 defects were found in single families. De novo pathogenic variants account for about 10% of individuals with ADPKD in adulthood (Neumann et al. 2012. PubMed ID: 22367170).
Monoallelic loss-of-function (LoF) IFT140 variants were recently found to result in an atypical (mild) form of ADPKD (Senum et al. 2022. PubMed ID: 34890546). Prior to this finding, this gene has been known to be associated with autosomal recessive conditions consisting of retinitis pigmentosa and short-rib thoracic dysplasia with or without polydactyly. The IFT140 gene encodes a subunit of intraflagellar transport complex A (IFTA), which is among the proteins involved in retrograde ciliary transport. Genetic defects of IFT140 occur throughout the whole coding region and include missense, nonsense, splicing variants, and small deletion/insertions. Large deletion and duplication have also been reported. After PKD1 and PKD2, IFT140 LoF variants likely represent the third most common cause of cystic kidney disease (Senum et al. 2022. PubMed ID: 34890546).
Monoallelic loss-of-function (LoF) ALG5 variants were also recently found to cause ADPKD-spectrum disorder characterized by multiple small kidney cysts, progressive interstitial fibrosis, and kidney function decline (Lemoine et al. 2022. PubMed ID: 35896117). The ALG5 gene encodes dolichyl-phosphate beta-glycosyltransferase, which is involved in N-glycosylation as a posttranslational modification of many glycoproteins. To date, documented genetic defects of ALG5 include missense and premature protein termination variants.
In addition, monoallelic loss-of-function (LoF) variants in the ALG8 and ALG9 genes were reported in relation to ADPKD (Besse et al. 2017. PubMed ID: 28375157; Besse et al. 2019. PubMed ID: 31395617). Currently there is limited (ALG8) or moderate (ALG9) evidence to support the gene-disease relationship (https://www.clinicalgenome.org/). For example, a study showed that patients heterozygous for ALG8 pathogenic or likely pathogenic variants are at increased risk of PKD on imaging but do not have an International Classification of Disease (ICD) diagnosis of PKD or polycystic liver disease (PLD) (https://www.medrxiv.org/content/10.1101/2022.07.13.22277451v1.full). Prior to these findings, ALG8 has been associated with autosomal recessive congenital disorder of glycosylation type Ih (OMIM #608104) and ALG9 with autosomal recessive congenital disorder of glycosylation type Il (OMIM #608776).
The GANAB gene encodes glucosidase II subunit alpha, defects of which possibly results in disruption of the maturation of polycystin-1 (the PKD1-encoded protein). Documented pathogenic variants in GANAB include truncating changes (nonsense, canonical splicing variants and frame-shifting small deletion/insertions) and missense substitutions (Human Gene Mutation Database). No large deletions or duplications have been reported yet.
The DNAJB11 gene encodes a co-factor of BiP, a key chaperone in the endoplasmic reticulum that controls folding, trafficking and degradation of secreted and membrane proteins. Documented pathogenic variants in DNAJB11 include truncating changes (nonsense and frame-shifting small deletion/insertions) and missense substitutions (Cornec-Le Gall et al. 2018. PubMed ID: 29706351). No large deletions or duplications have been reported yet.
HNF1B-related diseases are inherited in an autosomal dominant manner. The HNF1B gene encodes hepatocyte nuclear factor-1-beta (HNF1B), also known as transcription factor-2 (TCF2), which is a member of the homeodomain-containing superfamily of transcription factors and is an essential factor for embryogenesis of the kidney, pancreas, and liver. Genetic defects of HNF1B throughout the whole coding region include missense, nonsense, splicing variants, and small deletion/insertions. In addition, large deletions encompassing multiple exons or the whole HNF1B gene have been commonly reported (Human Gene Mutation Database; Bellanné-Chantelot et al. 2005. PubMed ID: 16249435). De novo HNF1B pathogenic variants are common, accounting for up to 50% of cases.
PKHD1 is the primary causative gene for ARPKD (Bergmann. 2017. PubMed ID: 29479522; Ward et al. 2002. PubMed ID: 11919560). Accounting for a small fraction of genetically positive cases, DZIP1L was newly identified as the second causative gene for ARPKD (Lu et al. 2017. PubMed ID: 28530676; Hartung and Guay-Woodford. 2017. PubMed ID: 28736432).
The PKHD1 gene encodes fibrocystin, a ciliary-localized membrane protein involved in a wide range of cellular functions including cell-to-cell adhesion and proliferation, acting as a membrane-bound receptor, and microtubule organization and/or in mechano- or chemosensation (Bergmann. 2017. PubMed ID: 29479522). Documented pathogenic variants in PKHD1 include truncating changes (nonsense, typical splicing variants and frame-shifting small deletion/insertions) and missense substitutions throughout the length of the gene (Human Gene Mutation Database). Multi-exon deletions and duplications occur, but are relatively rare (probably <5% of all pathogenic variants) (Bergmann et al. 2005. PubMed ID: 16199545). No obvious genotype-phenotype correlations have been established to date, but patients with two protein-truncating variants usually have the most severe disease with perinatal or neonatal mortality.
The DZIP1L gene encodes DAZ interacting protein 1?like protein, the impairment of which is associated with ciliary trafficking defects and renal cystogenesis. Documented pathogenic variants in DZIP1L include truncating changes (nonsense variants and frame-shifting small deletion/insertions) and missense substitutions (Lu et al. 2017. PubMed ID: 28530676). No large deletions or duplications have been reported yet.
Heterozygous missense variants in the kinase domain of the serine/threonine kinase NEK8 have been associated with an autosomal dominant form of polycystic kidney disease (Claus et al. 2023. PubMed ID: 37598857). Biallelic variants in CYS1 have been associated with autosomal recessive polycystic kidney disease (ARPKD), but currently the evidence is limited (Yang et al. 2021. PubMed ID: 34521872).
Clinical Sensitivity - Sequencing with CNV PGxome
In two large cohort studies, the overall pathogenic variants detection rate of PKD1 and PKD2 is about 89%, in which defects in PKD1 and PKD2 explain approximately 85% and 15% of genetically positive autosomal dominant polycystic kidney disease (ADPKD) cases, respectively (Rossetti et al. 2007. PubMed ID: 17582161; Audrézet et al. 2012. PubMed ID: 22508176). Large deletions and duplications in PKD1 and PKD2 are relatively rare (<4% of all pathogenic variants) in ADPKD patients (Bataille et al. 2011. PubMed ID: 22008521; Audrézet et al. 2012. PubMed ID: 22508176).
Since we primarily use Next Generation Sequencing (NGS) to test the PKD1 gene (see Testing Strategy section), gene conversions can be missed. However, our internal data suggested gene conversions are rare (<0.5%) in PKD1. These events have been found by long-range PCR based Sanger sequencing, but not by NGS only. Therefore, to increase detection rate (but by a very limited amount) of PKD1 pathogenic variants, Sanger sequencing for exons 1 to 33 (homologous regions) of PKD1 may be ordered.
After PKD1 and PKD2, IFT140 LoF variants likely represent the third most common cause of cystic kidney disease, for cystic kidney disease, accounting for >1% of ADPKD-spectrum-affected individuals (Senum et al. 2022. PubMed ID: 34890546).
Defects in the GANAB gene account for another ~0.3% of total ADPKD (~3% of genetically unexplained ADPKD-affected families by PKD1 and PKD2 pathogenic variants) (Porath et al. 2016. PubMed ID: 27259053). No large deletions or duplications at GANAB have been reported yet.
After the identification of DNAJB11 as a new causative gene for ADPKD in two index families, analysis of an additional 591 genetically unresolved ADPKD families found five (~1%) families with pathogenic variants in DNAJB11 (Cornec-Le Gall et al. 2018. PubMed ID: 29706351). No large deletions or duplications at DNAJB11 have been reported yet.
HNF1B defects explain approximately 1% of all maturity onset diabetes of the young cases (McDonald and Ellard. 2013. PubMed ID: 23878349). HNF1B pathogenic variants were found via Sanger sequencing in up to 7% of patients/fetuses with renal hypodysplasia in three large cohort studies (Weber et al. 2006. PubMed ID: 16971658; Thomas et al. 2011. PubMed ID: 21380624; Madariaga et al. 2013. PubMed ID: 23539225). Large deletions encompassing multiple exons or the whole HNF1B gene have been commonly reported (Human Gene Mutation Database; Bellanné-Chantelot et al. 2005. PubMed ID: 16249435).
Concurrent HNF1B and PKD1 pathogenic variants have been reported to have an aggravating effect on a patient's phenotypes and explain phenotypic variability within PKD-affected family members (Bergmann et al. 2011. PubMed ID: 22034641). However, this has been only reported in a limited number of cases and the prevalence of this effect is still unknown in a larger cohort of PKD patients.
Homozygous or compound heterozygous pathogenic variants in PKHD1 can be found in ~80% of ARPKD patients regardless of disease severity. Approximately 95% of affected individuals were found to have at least one pathogenic variant in PKHD1 (Bergmann. 2017. PubMed ID: 29479522). Multi-exon deletions and duplications occur, but are relatively rare (probably <5% of all pathogenic variants) (Bergmann et al. 2005. PubMed ID: 16199545).
Defects in the DZIP1L gene were found in only two of 743 (~0.3%) unrelated individuals with suspected ARPKD or sporadic PKD (Lu et al. 2017. PubMed ID: 28530676). No large deletions or duplications at DZIP1L have been reported yet.
Testing Strategy
This test is performed using Next-Gen sequencing with additional Sanger sequencing as necessary.
DNA analysis of the PKD1 gene is complicated and challenging due to the presence of several PKD1 pseudogenes. There is high sequence similarity of exons 1 to 33 between PKD1 and its pseudogenes (Audrézet et al. 2012. PubMed ID: 22508176). We have validated Next Generation Sequencing (NGS) to reliably sequence these exons.
For the PKD1 gene, including exons 1 to 33 (homologous regions), we primarily use Next Generation Sequencing (NGS) (~96%) complimented with Sanger sequencing for low-coverage regions (~4%). For any pathogenic, likely pathogenic, and uncertain variants found in exons 1 to 33 (homologous regions) via NGS, we use long-range PCR based Sanger sequencing to confirm them. Therefore, this test provides full coverage of all coding exons of the PKD1 gene plus 10 bases of flanking noncoding DNA in all available transcripts along with other non-coding regions in which pathogenic variants have been identified at PreventionGenetics or reported elsewhere. We define full coverage as >20X NGS reads or Sanger sequencing. PGnome panels typically provide slightly increased coverage over the PGxome equivalent. PGnome sequencing panels have the added benefit of additional analysis and reporting of deep intronic regions (where applicable).
Due to homologous sequence, gene conversion events in the PKD1 gene have been reported in the literature and found at PreventionGenetics. Our internal data suggested gene conversions are rare (<0.5%) in PKD1. These events have been found by long-range PCR based Sanger sequencing, but not by NGS only. Therefore, Sanger sequencing for exons 1 to 33 (homologous regions) of PKD1 may also be ordered.
Regarding copy number variants (CNVs) analysis, because of the paucity of CNVs and the complicated nature of sequence in PKD1, CNV analysis for this gene can be performed via the multiplex ligation-dependent amplification (MLPA) assay with limited increased sensitivity (compared to Next-Gen sequencing CNV analysis), and can be ordered separately (Test #2058).
This panel provides 100% coverage of all coding exons of the genes listed plus 10 bases of flanking noncoding DNA in all available transcripts along with other non-coding regions in which pathogenic variants have been identified at PreventionGenetics or reported elsewhere. We define coverage as ≥20X NGS reads or Sanger sequencing. PGnome panels typically provide slightly increased coverage over the PGxome equivalent. PGnome sequencing panels have the added benefit of additional analysis and reporting of deep intronic regions (where applicable).
Dependent on the sequencing backbone selected for this testing, discounted reflex testing to any other similar backbone-based test is available (i.e., PGxome panel to whole PGxome; PGnome panel to whole PGnome).
Indications for Test
Candidates for this test are patients with polycystic kidney disease (PKD).
Candidates for this test are patients with polycystic kidney disease (PKD).
Genes
| Official Gene Symbol | OMIM ID |
|---|---|
| ALG5 | 604565 |
| ALG8 | 608103 |
| ALG9 | 606941 |
| CYS1 | 618713 |
| DNAJB11 | 611341 |
| DZIP1L | 617570 |
| GANAB | 104160 |
| HNF1B | 189907 |
| IFT140 | 614620 |
| NEK8 | 609799 |
| PKD1 | 601313 |
| PKD2 | 173910 |
| PKHD1 | 606702 |
| Inheritance | Abbreviation |
|---|---|
| Autosomal Dominant | AD |
| Autosomal Recessive | AR |
| X-Linked | XL |
| Mitochondrial | MT |
Diseases
Related Test
| Name |
|---|
| PGxome® |
| Autosomal Dominant Polycystic Kidney Disease via the PKD1 Gene |
Citations
- Ariyurek et al. 2004. PubMed ID: 14695542
- Audrézet et al. 2012. PubMed ID: 22508176
- Audrézet et al. 2016. PubMed ID: 26139440
- Bataille et al. 2011. PubMed ID: 22008521
- Bellanné-Chantelot et al. 2005. PubMed ID: 16249435
- Bergmann et al. 2005. PubMed ID: 16199545
- Bergmann et al. 2011. PubMed ID: 22034641
- Bergmann. 2017. PubMed ID: 29479522
- Besse et al. 2017. PubMed ID: 28375157
- Besse et al. 2019. PubMed ID: 31395617
- Claus et al. 2023. PubMed ID: 37598857
- Cornec-Le Gall et al. 2018. PubMed ID: 29706351
- Harris et al. 2011. PubMed ID: 20301424
- Hartung and Guay-Woodford. 2017. PubMed ID: 28736432
- Horikawa et al. 1997. PubMed ID: 9398836
- Human Gene Mutation Database (Bio-base).
- Lemoine et al. 2022. PubMed ID: 35896117
- Lu et al. 2017. PubMed ID: 28530676
- Madariaga et al. 2013. PubMed ID: 23539225
- McDonald and Ellard. 2013. PubMed ID: 23878349
- Neumann et al. 2012. PubMed ID: 22367170
- Porath et al. 2016. PubMed ID: 27259053
- Rossetti et al. 2007. PubMed ID: 17582161
- Rossetti et al. 2009. PubMed ID: 19165178
- Senum et al. 2022. PubMed ID: 34890546
- Sweeney et al. 1993. PubMed ID: 20301501
- Thomas et al. 2011. PubMed ID: 21380624
- Vivante et al. 2014. PubMed ID: 24398540
- Vujic et al. 2010. PubMed ID: 20558538
- Ward et al. 2002. PubMed ID: 11919560
- Weber et al. 2006. PubMed ID: 16971658
- Yang et al. 2021. PubMed ID: 34521872
Ordering/Specimens
Ordering Options
We offer several options when ordering sequencing tests. For more information on these options, see our Ordering Instructions page. To view available options, click on the Order Options button within the test description.
myPrevent - Online Ordering
- The test can be added to your online orders in the Summary and Pricing section.
- Once the test has been added log in to myPrevent to fill out an online requisition form.
- PGnome sequencing panels can be ordered via the myPrevent portal only at this time.
Requisition Form
- A completed requisition form must accompany all specimens.
- Billing information along with specimen and shipping instructions are within the requisition form.
- All testing must be ordered by a qualified healthcare provider.
For Requisition Forms, visit our Forms page
If ordering a Duo or Trio test, the proband and all comparator samples are required to initiate testing. If we do not receive all required samples for the test ordered within 21 days, we will convert the order to the most effective testing strategy with the samples available. Prior authorization and/or billing in place may be impacted by a change in test code.
Specimen Types
Specimen Requirements and Shipping Details
PGxome (Exome) Sequencing Panel
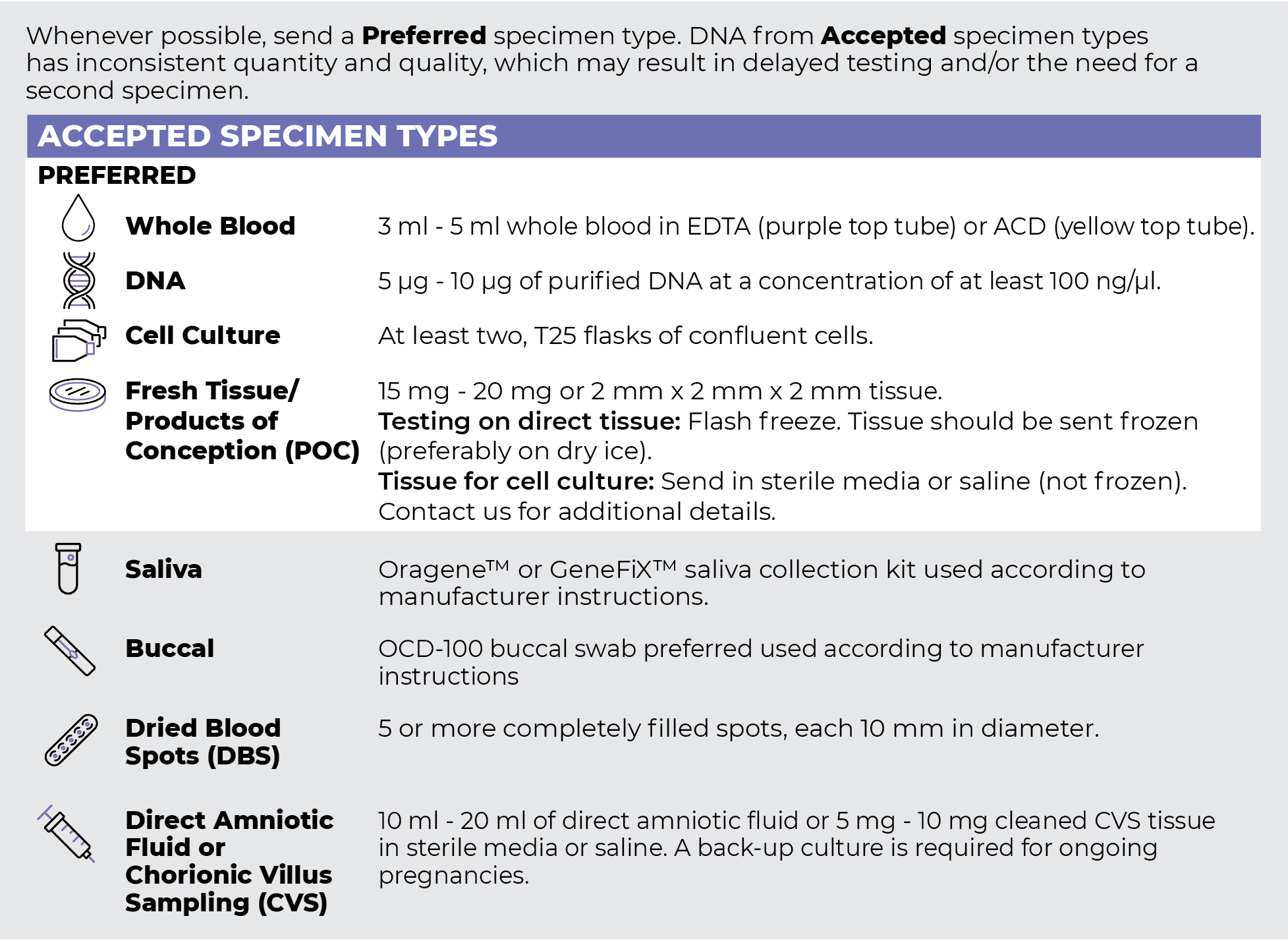
PGnome (Genome) Sequencing Panel

ORDER OPTIONS
View Ordering Instructions1) Select Test Type
2) Select Additional Test Options
No Additional Test Options are available for this test.